O*NET
Eric Lawler
June 01, 2021
Filed under “Dross”
There exists a thing known as O*NET, a project by the US Department of Labor/Employment and Training Administration (helpfully abbreviated as USDOL/ETA) to help people navigate the massive, 1,000+ set of careers that exist in our modern workforce.
On a lark, Shelley and I took the tests. Just in case software engineering leadership is turned over to machine learning algorithms and I need a backup career.
Our results
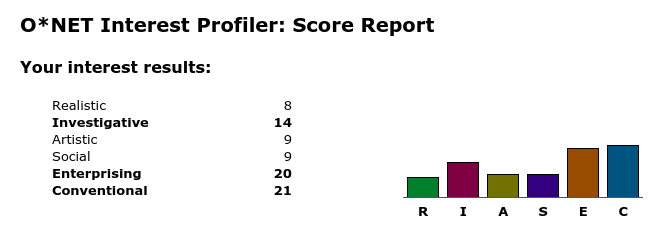 I scored high in Enterprising and Conventional work, with Investigative work a distant third. I am uninterested in working with my hands, the arts, or social work that enjoys “working with people more than working with objects, machines, or information.”
I scored high in Enterprising and Conventional work, with Investigative work a distant third. I am uninterested in working with my hands, the arts, or social work that enjoys “working with people more than working with objects, machines, or information.”
The combination of traits from the E and C categories are pretty on-point:
- Persuading and leading people
- Making decisions
- Taking risks for profits
- Following a strong leader
Yes! I’ll take all of that, please.
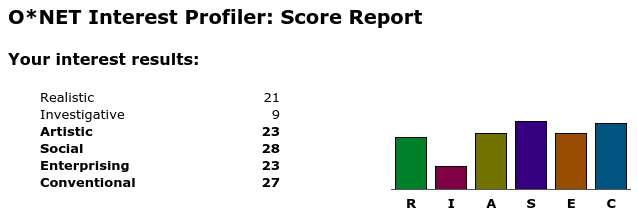 She had an easier time picturing herself doing different careers and scored higher across the board… except in Investigative work, which had no appeal to her. Social work gets a strong “Yes, please,” as well as work that borders on the monotonous, with clear goals and predictable processes.
She had an easier time picturing herself doing different careers and scored higher across the board… except in Investigative work, which had no appeal to her. Social work gets a strong “Yes, please,” as well as work that borders on the monotonous, with clear goals and predictable processes.
The most amusing part was that I rated “I would like to investigate the cause of a fire” as a 😀, the highest score, and “I would like to fight forest fires” as 😵, the lowest. Shelley flipped the two.
Madness! Imagine wanting to be in the wilderness, battling fires alongside California’s bravest prisoners, bulldozing trees and establishing perimeters measuring miles on each side. All in the comfort of a 110* Santa Ana wind. Orrrrrr imagine wandering through a burned-out husk of a warehouse, stopping to stoop down and carefully pick through particularly interesting detritus, carefully assembling a mental model of where the fire started and how it traveled… Yeah, that’s not a difficult one to choose between.
…if you’re curious, my backup career is officially Air Traffic Controller. Not a bad suggestion, USDOL/ETA.